Watch 特性初体验
启动空集群并更新 key:
使用 etcdctl put hello world1 和 etcdctl put hello world2 命令更新 key hello。
监听 key 的历史修改记录:
使用 etcdctl watch hello -w=json --rev=1 命令带版本号监听 key hello,可以获取到该 key 的所有历史修改记录。
输出结果展示了两次修改事件,每个事件包含 key、value 及各种版本号信息,可以通过比较 create_revision 和 mod_revision 来区分是添加(add)还是更新(update)事件。
$ etcdctl watch hello -w=json --rev=1
{
"Events":[
{
"kv":{
"key":"aGVsbG8=",
"create_revision":2,
"mod_revision":2,
"version":1,
"value":"d29ybGQx"
}
},
{
"kv":{
"key":"aGVsbG8=",
"create_revision":2,
"mod_revision":3,
"version":2,
"value":"d29ybGQy"
}
}
],
"CompactRevision":0,
"Canceled":false,
"Created":false
}
持续监听新变更:
执行增量 put hello 修改操作后,watch 命令将持续输出最新的变更事件。
从以上初体验中,你可以看到,基于 Watch 特性,你可以快速获取到你感兴趣的数据变化事件,这也是 Kubernetes 控制器工作的核心基础。在这过程中,其实有以下四大核心问题:
Client 获取事件的机制:
轮询模式 vs 推送模式:etcd 使用推送模式而非轮询模式。推送模式的优点在于实时性强,能够及时响应变化;缺点是可能增加服务器负担。轮询模式则相反,优点是实现简单但实时性较差。
事件存储与保留时间:
事件存储:事件如何存储及保留多久是一个重要考量点。Watch 命令中的版本号用于指定从哪个版本开始监听,确保能获取到指定版本后的所有变更。
作用:版本号帮助客户端精确地追踪感兴趣的事件,避免遗漏或重复处理事件。
网络波动和事件堆积处理:
当客户端与服务器之间出现短暂网络波动导致事件堆积时,服务器端是否会丢弃事件?如果监听的历史版本号不再存在,代码应如何处理这些问题?
解决方案涉及如何设计健壮的重连和事件恢复机制,以确保在网络恢复后能继续正确监听。
Watcher 管理与高效查找:
如果创建了上万个 watcher 监听 key 变化,当服务器收到写请求后,如何根据变化的 key 快速找到对应的 watcher 是一个技术挑战。
高效管理 watcher 并快速匹配相关变化,对于提高系统性能至关重要。
这些问题的答案揭示了 etcd Watch 特性的核心实现原理,理解这些可以帮助开发者更好地利用 etcd 的 Watch 功能,以及了解其他分布式存储系统的类似特性。接下来的内容将进一步探讨这些问题的具体解决方案。
获取事件机制
Client 获取事件机制
etcd v2:client 轮询模式
使用 HTTP/1.x 协议,每个 watcher 对应一个 TCP 连接。
客户端通过长连接定时轮询服务器以获取最新的数据变化事件。
缺点:当存在大量 watcher 时,即使在空负载下也会产生显著的 QPS,导致服务器资源(如 socket 和内存)的过度消耗,影响扩展性和稳定性。
etcd v3:server 流式推送
引入基于 HTTP/2 的 gRPC 协议,支持双向流式通信,解决了 etcd v2 中的扩展性和稳定性问题。
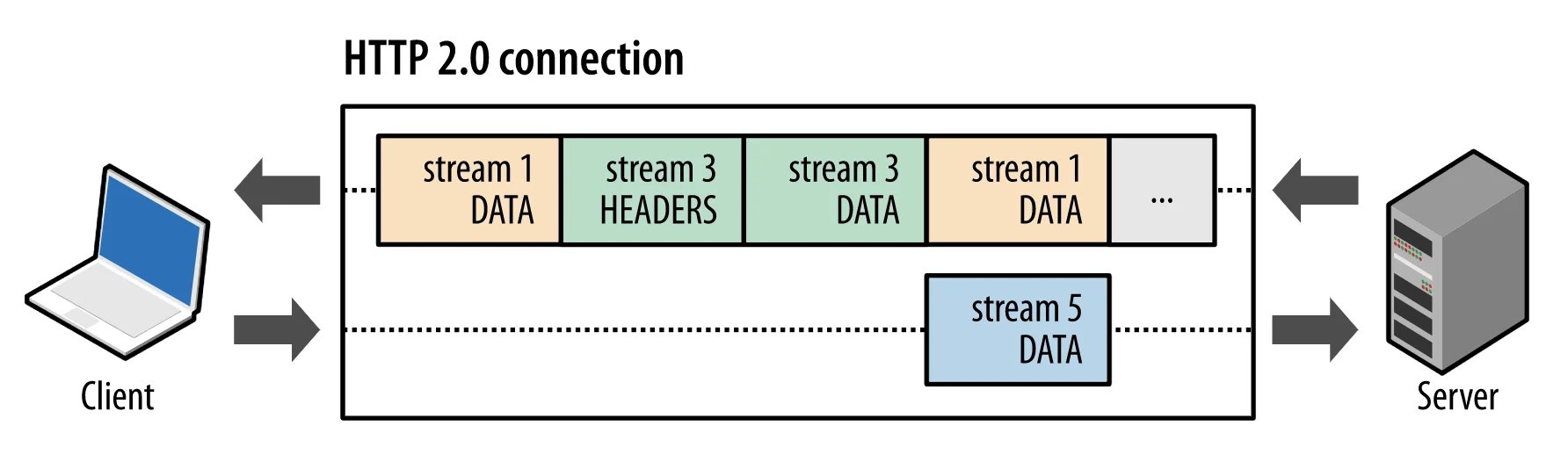
利用 HTTP/2 的多路复用特性,允许在一个 TCP 连接上并发传输多个独立的数据流(stream),每个流由一系列帧(frame)组成,这些帧可以交错发送并根据流 ID 重新组装成完整的消息。
实现了一个客户端/TCP 连接支持多个 gRPC Stream,每个 gRPC Stream 又可以支持多个 watcher,大大减少了服务器资源的占用,并提高了效率。
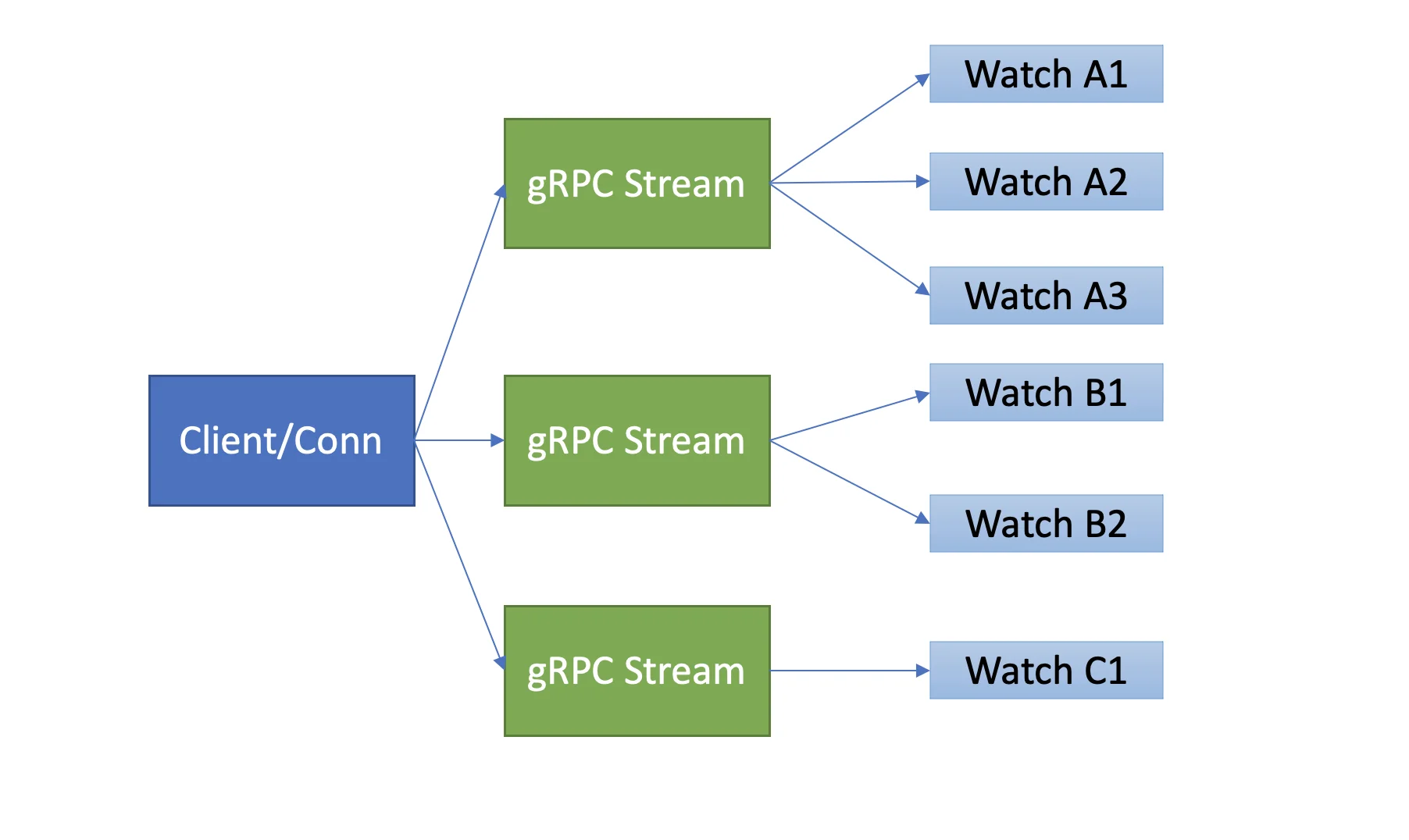
HTTP/2 多路复用机制
HTTP/2 帧与流:
HTTP 消息被分解为独立的帧,每个帧标识属于哪个流(Stream)。流由多个帧组成,每个流拥有唯一的 ID。
这种设计允许在同一连接上有多个并行的数据流,通过帧的流 ID 将交错发送的帧重组为完整的消息,从而实现了多路复用和乱序发送。
etcd v3 Watch 机制的优点
性能优化:从客户端轮询改为服务器推送模式,降低了服务器端的资源消耗。
简化开发复杂度:尽管 Watch API 的复杂性有所增加,但 etcd 的 clientv3 库已经抽象出简单的 API(如 Watch、Close、RequestProgress),隐藏了底层交互细节,简化了开发者的工作。
自动重连与事件恢复:clientv3 库支持自动重连到健康节点,并使用之前接收的最大版本号创建新的 watcher,避免旧事件的重复播放。
通过这些改进,etcd v3 不仅提高了系统的可扩展性和稳定性,还提供了更高效、更灵活的事件监听机制,非常适合需要高可靠性和高性能的应用场景,如 Kubernetes 等分布式系统的核心组件。
事件历史版本存储
事件存储与历史版本保留
etcd v2 滑动窗口机制:
使用一个简单的环形数组来存储最近的历史事件版本。
当 key 被修改后,相关事件会被添加到数组中。如果超过 eventQueue 的容量(固定为1000),则淘汰最旧的事件。
示例代码展示了如何使用 EventHistory 结构体来管理事件队列。
type EventHistory struct {
Queue eventQueue
StartIndex uint64
LastIndex uint64
rwl sync.RWMutex
}缺点:只能保存有限的历史事件版本(最多1000条记录),在写请求较多或网络波动时容易导致事件丢失,需要进行昂贵的查询操作以恢复数据。
etcd v3 MVCC 机制:
引入了基于磁盘文件的持久化存储 boltdb 来保存每个 key 的所有历史修改版本。
相比于内存中的环形数组,MVCC 提供了更高的可靠性,重启后不会丢失历史事件。
可通过配置压缩策略来控制保存的历史版本数量。
版本号的作用
在 etcd v3 中,版本号作为逻辑时钟,用于增量同步数据。
当客户端由于网络异常等原因出现连接中断后,可以通过指定版本号从服务器端的 boltdb 中获取错过的历史事件,而无需全量同步。
这是 etcd Watch 机制实现增量同步的核心,极大地提高了系统在面对网络波动等异常情况下的稳定性和效率。
v2 与 v3 对比分析
etcd v2:依赖内存中的环形数组来保存有限的历史事件版本,虽然避免了大量内存占用,但在高负载或网络不稳定的情况下容易丢失事件,影响系统的可靠性和性能。
etcd v3:采用 MVCC 和 boltdb 实现了对历史版本的持久化存储,不仅解决了事件丢失的问题,还支持更灵活的历史版本管理,提升了系统的整体稳定性。
总的来说,etcd v3 的设计改进显著增强了 Watch 功能的可靠性和灵活性,特别适合如 Kubernetes 这样重度依赖 Watch 机制的应用场景。通过引入 MVCC 和持久化存储,etcd 能够更好地处理大规模并发和网络波动带来的挑战
可靠的事件推送机制
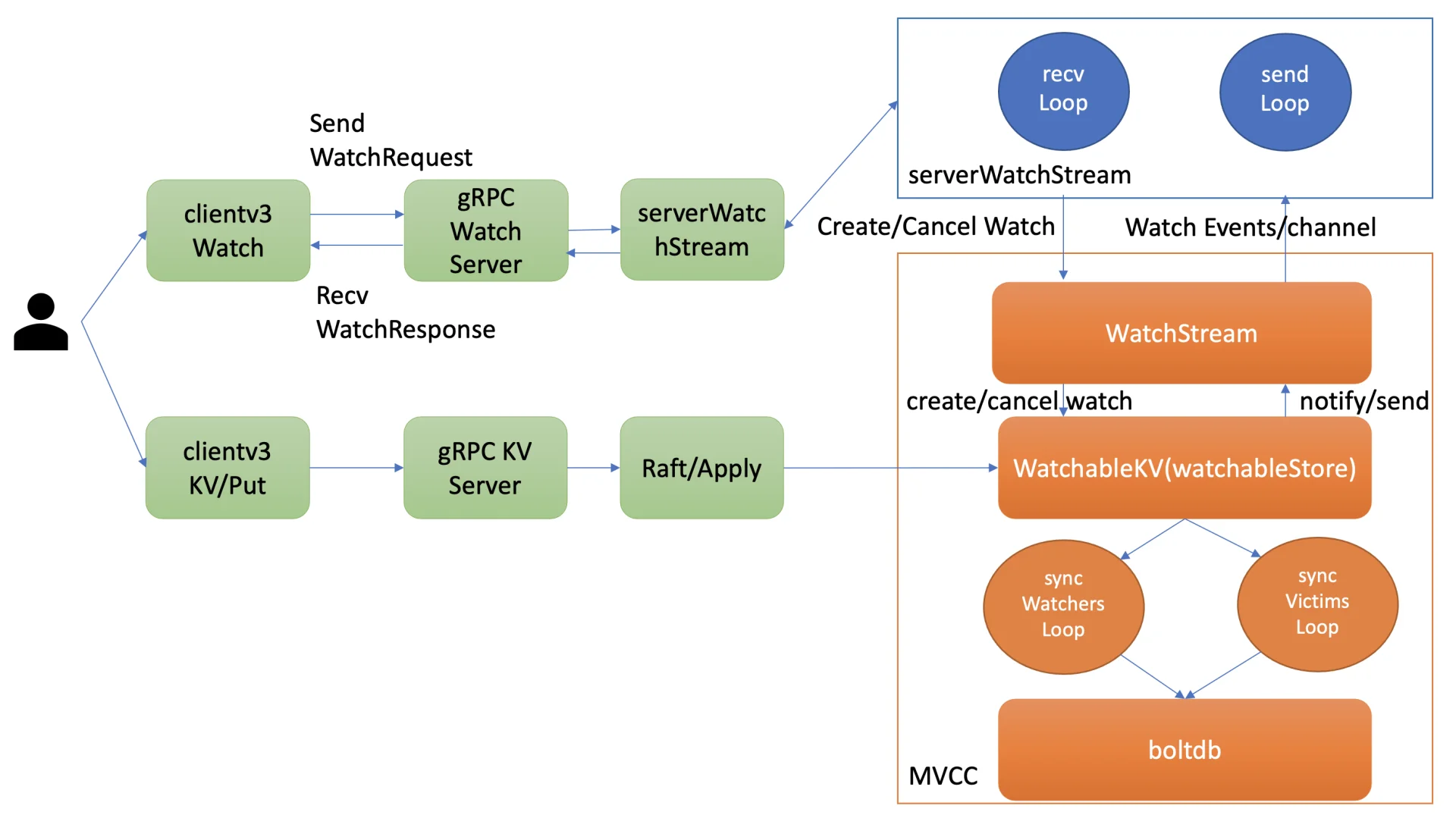
整体架构
Watch 请求处理流程:
当通过 etcdctl 或 API 发起一个 watch key 请求时,etcd 的 gRPCWatchServer 收到请求后会创建一个 serverWatchStream。
serverWatchStream 负责接收来自客户端的 create/cancel watcher 请求,并将从 MVCC 模块接收到的 Watch 事件转发给客户端。
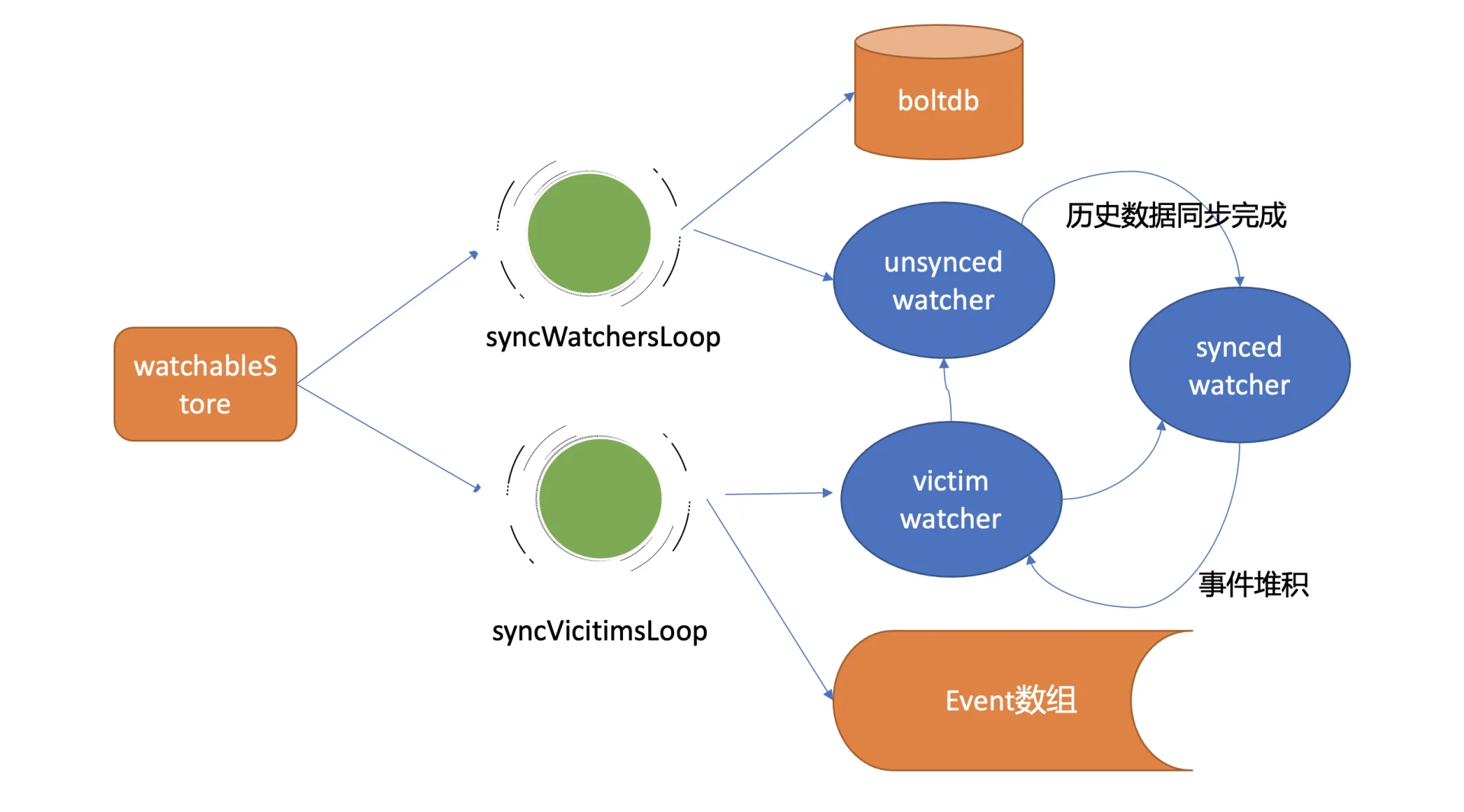
创建 watcher 后,它会被注册到 MVCC 的 WatchableKV 模块中,该模块负责运行 syncWatchersLoop 和 syncVictimsLoop goroutine 来确保事件的可靠推送。
Watcher 分类与管理
Synced Watcher:表示监听的数据已经同步完毕,正在等待新的变更。如果 watcher 未指定版本号或指定的版本号大于当前服务器版本号,则属于此类。
Unsynced Watcher:表示监听的数据还未完全同步,落后于最新数据变更。如果 watcher 指定的版本号小于当前服务器版本号,则属于此类。
最新事件推送机制
当 etcd 收到写请求并修改 key-value 数据时,在 MVCC 的 put 事务结束时,会生成相应的 Event 并调用 watchableStore.notify 函数来通知相关的 synced watcher。
notify 函数会匹配出监听过此 key 的 watcher,并且只有当事件中的版本号大于等于 watcher 监听的最小版本号时,才会将事件发送到 watcher 的事件 channel 中。
一旦事件被推送到 channel 中,serverWatchStream 的 sendLoop goroutine 就会监听到消息并将事件立即推送给客户端。
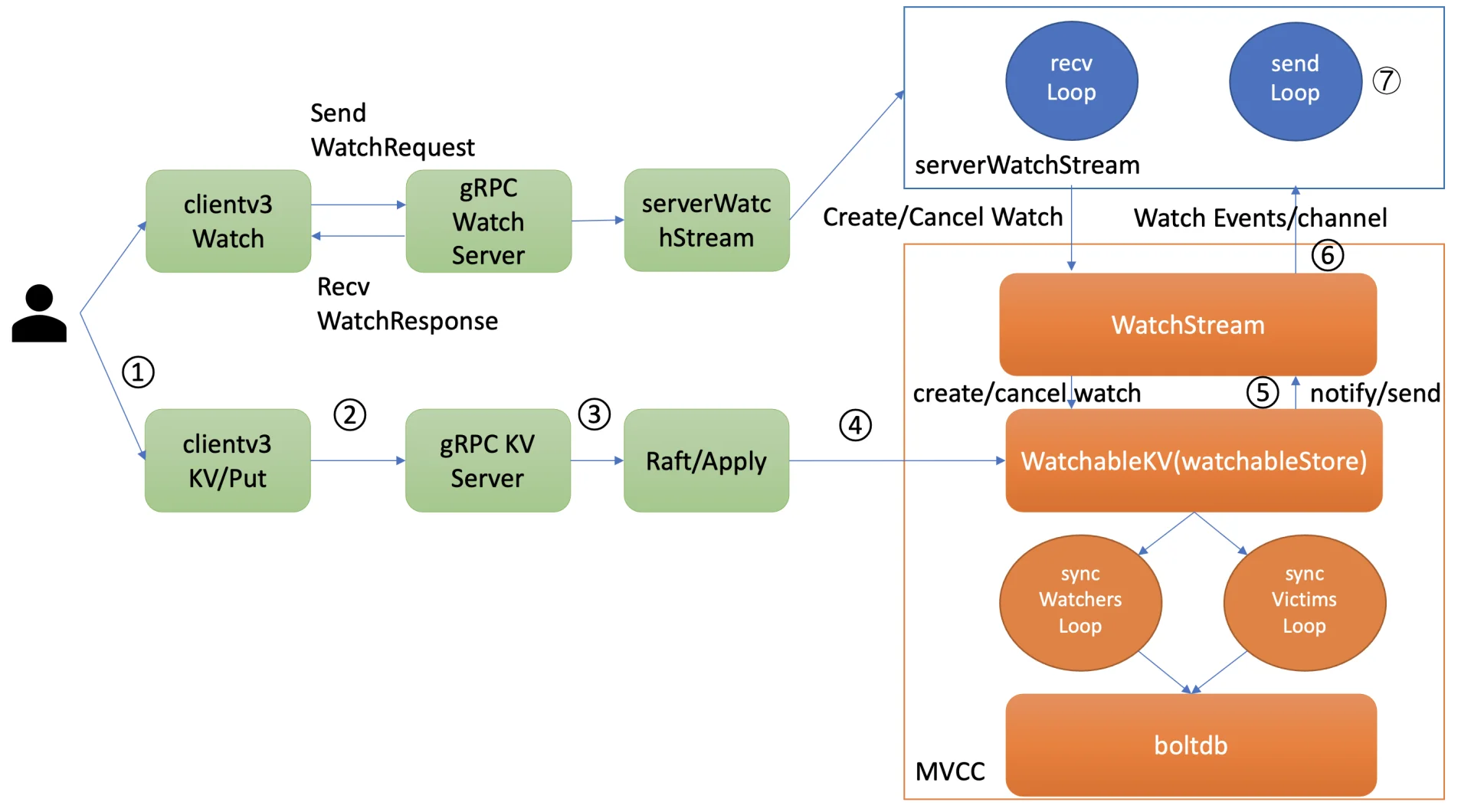
异常场景重试机制
如果由于网络波动或高负载导致事件 channel buffer 满了,etcd 不会丢弃事件,而是将受影响的 watcher 从 synced watcherGroup 移动到一个名为 victim 的 watcherBatch 结构中,并通过异步机制重试保证事件的可靠性。
syncVictimsLoop goroutine 遍历 victim watcherBatch 数据结构,尝试重新推送堆积的事件。如果推送失败,事件会再次加入到 victim watcherBatch 中等待下次重试;如果成功,则根据情况将 watcher 加入 unsynced 或 synced watcherGroup 中继续处理。
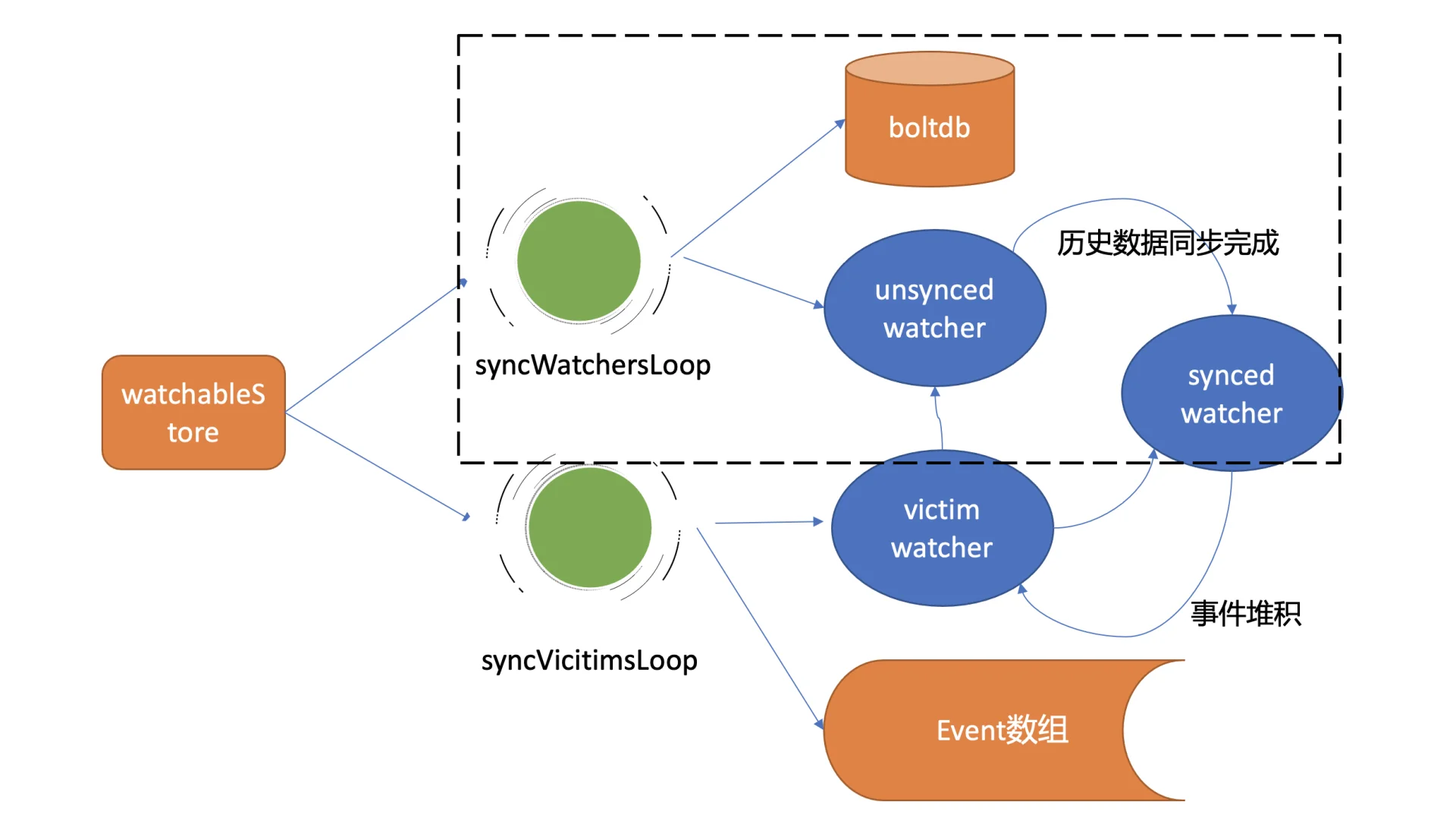
历史事件推送机制
syncWatchersLoop goroutine 负责处理 unsynced watcherGroup 中的历史事件推送。
它会选择一批 unsynced watcher 批量同步,找出这批 watcher 中监听的最小版本号,利用 boltdb 存储的 key-value 历史版本信息,通过指定查询的 key 范围来获取历史数据,并将其转换成事件发送给对应的 watcher。
完成后,watcher 从 unsynced watcherGroup 移除并添加到 synced watcherGroup 中。
这些机制共同确保了 etcd 的 Watch 功能能够在各种异常情况下保持高度的可靠性和效率,支持分布式系统(如 Kubernetes)的稳定运行。通过复杂度管理和问题拆分,etcd 实现了一个灵活且强大的 Watch 机制,能够有效应对网络波动、高负载等挑战。
高效的事件匹配
高效查找监听特定 key 的 watcher
问题背景:当 server 端收到写请求后,如何快速确定哪些 watcher 监听了这个变化的 key 是一个关键挑战。简单遍历所有 watcher 的方法时间复杂度为 O(N),在 watcher 数量较多时会导致性能瓶颈。
解决方案
使用 Map 和区间树的数据结构:
Map:etcd 使用 map 来记录监听单个 key 的 watcher,这种方法可以快速定位监听特定 key 的 watcher。
区间树(Interval Tree):考虑到 Watch 特性不仅支持监听单个 key,还支持监听 key 范围和 key 前缀,etcd 使用了区间树来存储监听范围的 watcher。区间树允许快速查找与某个 key 相交的所有区间,其时间复杂度为 O(LogN)。
具体实现:
当创建 watcher 请求时,如果该 watcher 监听的是一个 key 范围或前缀,则将这个范围插入到区间树中,区间的值保存了监听相同 key 范围的所有 watcher 集合(watcherSet)。
当产生事件时,etcd 首先从 map 中查找是否有 watcher 监听了该单个 key,然后从区间树中找出与此 key 相交的所有区间,并从中获取监听这些区间的 watcher 集合。
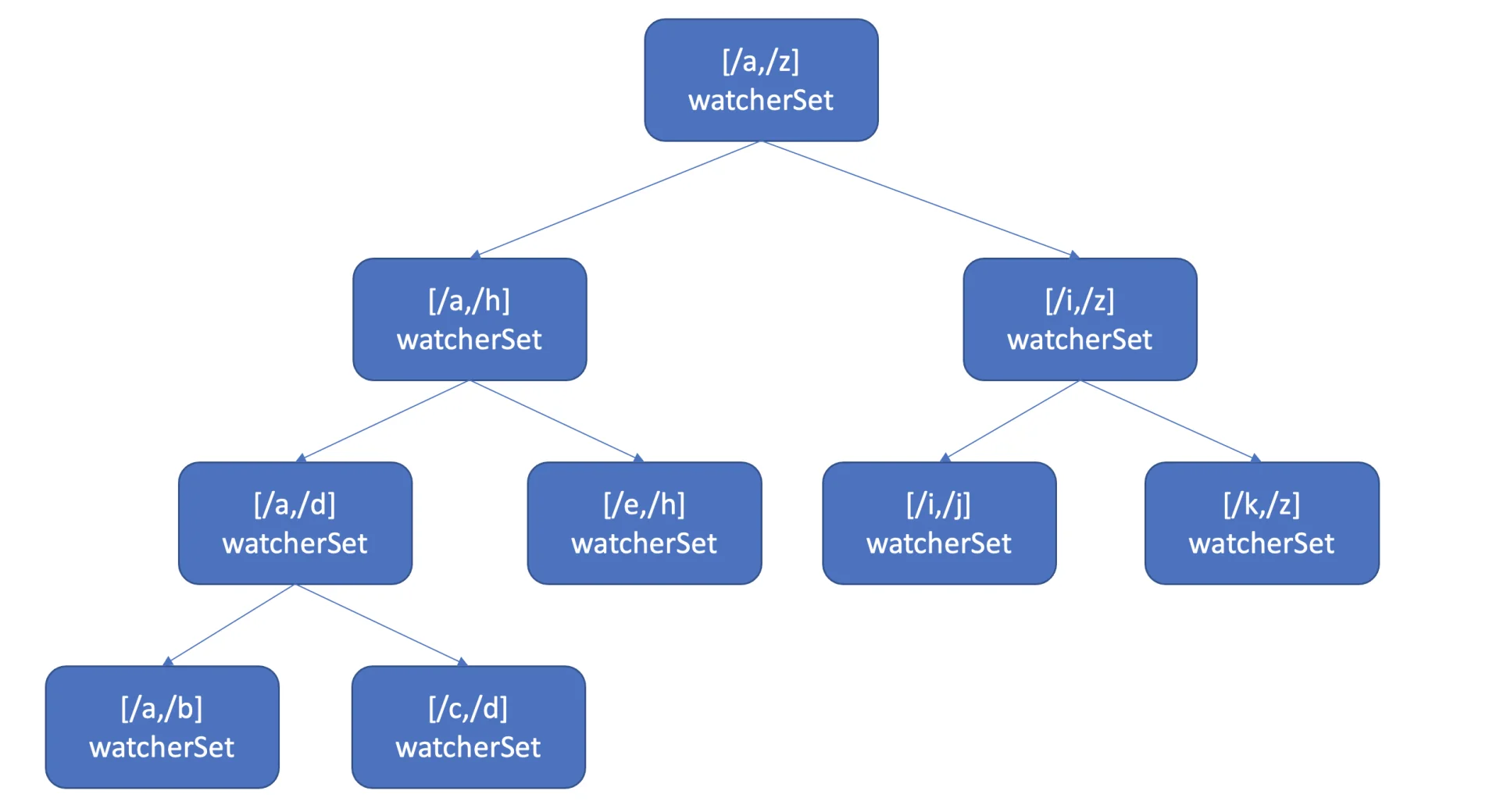
性能优化
这种基于 map 和区间树的方法使得 etcd 在处理 watcher 和事件匹配时具有良好的扩展性和效率,避免了在 watcher 数量较多的情况下出现性能瓶颈。
通过这种方式,etcd 可以在执行写事务结束时同步触发事件通知流程,而不会因为匹配 watcher 开销较大而严重影响性能。
综上所述,etcd 利用 map 和区间树这两种数据结构巧妙解决了在大量 watcher 存在的情况下快速找到监听特定 key 或 key 范围的 watcher 的问题,确保了系统在高负载情况下的稳定性和响应速度。这种设计特别适合需要高度可扩展性和高性能的分布式系统应用。
小结
四个核心问题及其解决方案
获取事件机制:
etcd v2:使用 HTTP/1.x 轮询机制,每个 watcher 对应一个 TCP 连接,导致大量连接数和潜在的丢事件问题,扩展性和稳定性较差。
etcd v3:采用基于 HTTP/2 的流式传输和多路复用技术,实现了单个连接支持多个 watcher,显著减少了连接数,并提高了系统的扩展性和稳定性。
事件历史版本存储:
etcd v2:使用滑动窗口机制保存最近的历史事件版本,存在固定的容量限制(如1000条记录),可能导致事件丢失。
etcd v3:通过 MVCC 机制将历史版本保存在磁盘中,提供了更稳定可靠的历史版本存储方案,增强了系统的扩展性和数据可靠性。
可靠的事件推送机制:
核心模块是 watchableStore,它将 watcher 分为 synced、unsynced 和 victim 三类,针对不同场景下的事件推送需求进行了分类管理。
使用多个后台异步循环 goroutine(如 syncWatchersLoop 和 syncVictimsLoop)负责不同类型 watcher 的事件推送,确保各类异常情况下变更事件不丢失,并按逻辑时钟版本号顺序推送给客户端。
事件与 watcher 的高效匹配:
为了提高性能,etcd 使用 map 来快速查找监听特定 key 的 watcher,同时利用区间树来处理监听 key 范围或前缀的情况。
区间树支持 O(LogN) 时间复杂度的快速查找,使得系统能够在大规模 watcher 场景下依然保持高效的事件与 watcher 匹配性能。
etcd watch 对优化思路以及对应关键点
优化思路:从 etcd v2 到 etcd v3 的演进过程中,通过引入 HTTP/2 的流式传输、MVCC 机制、以及对 watcher 的精细分类管理等优化措施,大大提升了 Watch 特性的扩展性、稳定性和性能。
关键点:watchableStore 模块通过合理的架构设计和多种后台异步循环 goroutine 的协同工作,确保了事件推送的高可靠性;而基于 map 和区间树的数据结构选择,则保证了在大规模应用场景下的高效事件与 watcher 匹配能力。
这些改进不仅解决了早期版本中的性能瓶颈和可靠性问题,也为依赖 etcd 的分布式系统(如 Kubernetes)提供了更加稳固的支持。
思考
业务场景是希望 agent 能通过 Watch 机制监听 server 端下发给它的任务信息,简要实现如下,你认为它存在哪些问题呢? 它一定能监听到 server 下发给其的所有任务信息吗?
taskPrefix := "/task/" + "Agent IP"
rsp, err := cli.Get(context.Background(), taskPrefix, clientv3.WithPrefix())
if err != nil {
log.Fatal(err)
}
// to do something
// ....
// Watch taskPrefix
rch := cli.Watch(context.Background(), taskPrefix, clientv3.WithPrefix())
for wresp := range rch {
for _, ev := range wresp.Events {
fmt.Printf("%s %q : %q\n", ev.Type, ev.Kv.Key, ev.Kv.Value)
}
}
答案:
可能存在的问题
上下文(Context)管理:
使用 context.Background() 创建了一个没有取消功能、超时控制的空上下文。在实际应用中,这可能导致资源泄露或者无法及时响应系统终止信号等问题。建议使用带有超时或可取消功能的上下文。
初始状态同步问题:
在启动 Watch 之前通过 Get 方法获取 /task/Agent IP 下的所有现有任务是一个合理的尝试,但是它并不能保证在调用 Watch 之前不会有新的任务被添加。这意味着可能会错过一些任务更新。
如果在执行 Get 和开始 Watch 的间隙有新的任务被添加,则这些任务将不会被立即发现。
Watch 起始版本号未指定:
当前代码中直接对 taskPrefix 进行了 Watch 操作,但没有指定起始版本号。如果 etcd 中已经存在大量的历史数据修改,并且这些修改对于 agent 来说也是重要的,那么不指定起始版本号可能会导致错过部分历史事件。
可以考虑在 Get 请求之后,根据返回结果中的修订版本号来设置 Watch 请求的起始版本号,从而避免错过任何更新。
错误处理不够健壮:
目前的错误处理仅是简单地记录致命错误并退出程序。在生产环境中,更灵活的错误处理策略可能是必要的,例如重试机制或降级处理。
网络波动或高负载下的可靠性:
在网络不稳定或服务器高负载的情况下,Watch 流程可能会中断,导致事件丢失。虽然 etcd 提供了一些机制来处理这种情况(如事件重试机制),但这段代码没有显示如何处理此类异常情况。
是否能监听到所有任务信息?
根据上述分析,该实现并不能保证一定能监听到 server 端下发给它的所有任务信息。特别是在初始化阶段,由于 Get 和 Watch 之间可能存在的时间差,某些任务更新可能会被遗漏。此外,如果没有正确设置 Watch 的起始版本号,也可能导致错过一些历史任务更新。
为了改进这一实现,可以考虑以下几点:
使用具有超时控制和取消功能的上下文。
在执行 Get 后,利用返回的修订版本号作为 Watch 请求的起始版本号,确保不会错过任何更新。
增强错误处理逻辑,加入适当的重试机制。
对于长时间运行的服务,考虑如何优雅地处理网络波动或服务重启等场景,确保服务的连续性和数据的一致性。
本文内容摘抄自极客时间专栏 etcd 实战课